正则表达式
简介
正则表达式,又称规则表达式(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(“元字符”)。
正则表达式是一种用来描述规则的表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及而来的,后广泛用于其他编程语言中。
正则的底层原理,就是使用状态机的思想进行模式匹配。大家可以利用regexper.com这个工具很好地可视化自己写的正则表达式的状态机。
语法
正则表达式的基本组成元素可以分为:字符 和 元字符。
- 字符,就是基础的计算机字符编码,通常正则表达式里面使用的就是数字、英文字母。
- 元字符,也被称为特殊字符,是一些用来表示特殊语义的字符。如^表示非,|表示或等。
字符
单字符
单个字符的映射关系是一对一, 最简单的正则就是单个字符。
部分特殊语义字符需要通过\来转义
| 特殊字符 | 正则表达式 | 记忆方式 |
|---|---|---|
| 换行符 | \n | new line |
| 换页符 | \f | form feed |
| 回车符 | \r | return |
| 空白符 | \s | space |
| 制表符 | \t | tab |
| 垂直制表符 | \v | vertical tab |
| 回退符 | [\b] | backspace,之所以使用[]符号是避免和\b重复 |
多字符
使用集合区间和通配符的方式就可以实现一对多的匹配。
集合的定义方式是使用中括号 [ 和 ] 。如 /[123]/ 这个正则就能同时匹配1,2,3三个字符。如果想匹配所有的数字,可以用元字符 - 就可以用来表示区间范围,用 /[0-9]/ 就能匹配所有的数字, /[a-z]/ 则可以匹配所有的英文小写字母。
即便有了集合和区间的定义方式,如果要同时匹配多种字符也要一一列举,这是低效的。所以在正则表达式里衍生了一批用来同时匹配多个字符的简便正则表达式:
| 匹配区间 | 正则表达式 | 记忆方式 |
|---|---|---|
| 除了换行符之外的任何字符 | . | 句号,除了句子结束符 |
| 单个数字, [0-9] | \d | digit |
| 除了[0-9] | \D | not digit |
| 包括下划线在内的单个字符,[A-Za-z0-9_] | \w | word |
| 非单字字符 | \W | not word |
| 匹配空白字符,包括空格、制表符、换页符和换行符 | \s | space |
| 匹配非空白字符 | \S | not space |
逻辑处理
| 逻辑关系 | 正则元字符 |
|---|---|
| 与 | 无 |
| 非 | [^regex]和! |
| 或 | | |
循环和重复
通过定义单个规则的出现次数,可以简化正则
| 匹配规则 | 元字符 | 联想方式 |
|---|---|---|
| 0次或1次 | ? | 有无 |
| 0次或无数次 | * | 星空无数或什么都看不见 |
| 1次或无数次 | + | +1 |
| 特定次数 | {x}, {min, max} | 区间 |
特定次数:
1 | |
位置边界
对于正则的匹配,我们可以指定匹配的开始和结束位置
| 边界和标志 | 正则表达式 | 记忆方式 |
|---|---|---|
| 单词边界 | \b | boundary |
| 非单词边界 | \B | not boundary |
| 字符串开头 | ^ | 左上角 |
| 字符串结尾 | $ | |
| 多行模式 | m标志 | multiple of lines |
| 忽略大小写 | i标志 | ignore case, case-insensitive |
| 全局模式 | g标志 | global,多次匹配而非单次 |
说明:标志通常是作为独立参数,比如:
- JAVA中
Pattern.compile(String regex, int flags); - JavaScript中
str.replace(/(ab)c/g, 'a');
子表达式
分组
- 子表达式可以通过
()进行分组 - 对于分组的表达式我们可以使用
\1\2…的形式来引用,\0表示引用整个表达式 - 在替换字符串时,语法上有些许区别,用$1,$2…来引用要被替换的字符串。
举例:
1 | |

- 子表达式可以通过
(?:regex)避免进行分组,也就是说分组时会跳过此表达式不编号
举例:
1 | |
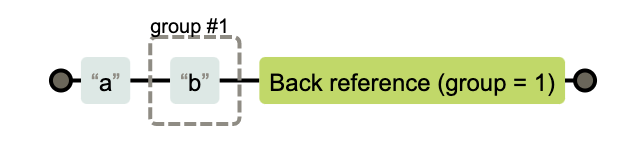
回溯引用
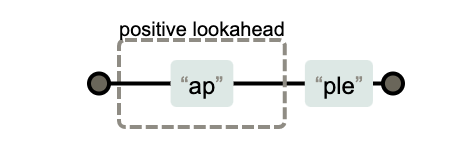
- 前向查找
前向查找(lookahead)是用来限制后缀。以(?=regex)包含的子表达式,从子表达式的位置开始向前查找符合规则的字串。
举例:
1 | |
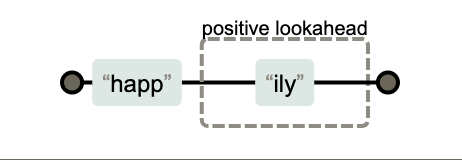
- 后向查找
后向查找(lookbehind)是用来限制前缀。以(?<=regex)包含的子表达式,从子表达式的位置开始向后查找符合规则的字串。
举例:
1 | |
| 回溯查找 | 正则 | 记忆方式 |
|---|---|---|
| 引用 | \0,\1,\2 和 $0, $1, $2 | 转义+数字 |
| 非捕获组 | (?:) | 引用(:) |
| 前向查找 | (?=) | 后缀(=) |
| 前向负查找 | (?!) | 后缀(!=) |
| 后向查找 | (?<=) | <左括号,前缀(=) |
| 后向负查找 | (?<!) | <左括号,前缀(!=) |
参考资料
正则表达式
https://oabern.github.io/posts/20220707794273428/